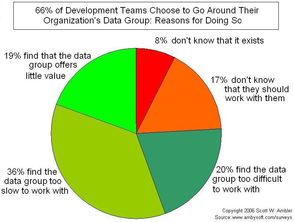
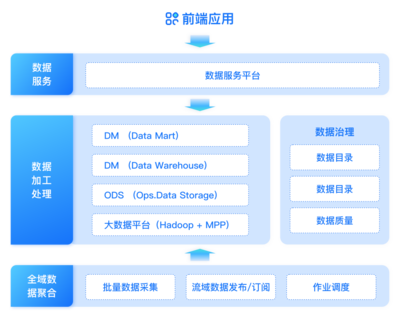
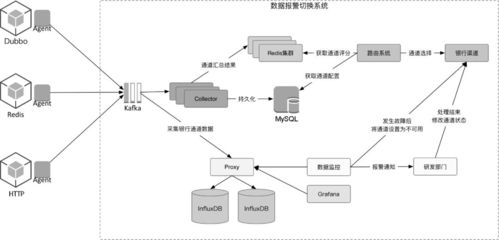
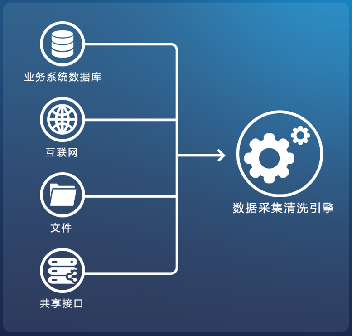
6大頂尖大數(shù)據(jù)處理與分析工具與服務(wù) 賦能智能決策,釋放數(shù)據(jù)價值
在數(shù)據(jù)爆炸的時代,高效、強(qiáng)大的數(shù)據(jù)處理與分析工具是企業(yè)挖掘數(shù)據(jù)金礦、驅(qū)動業(yè)務(wù)增長的核心引擎。從海量數(shù)據(jù)的存儲、清洗、計算到可視化分析,一系列成熟的工具和服務(wù)構(gòu)成了現(xiàn)代數(shù)據(jù)基礎(chǔ)設(shè)施的支柱。本文將深入介紹六個目前業(yè)界公認(rèn)的、用于大數(shù)據(jù)處理與分析的最佳工具及服務(wù)平臺,為您的技術(shù)選型提供參考。
1. Apache Hadoop:分布式處理的基石
作為開源分布式計算框架的鼻祖之一,Hadoop以其HDFS(分布式文件系統(tǒng))和MapReduce(編程模型)為核心,能夠以可靠、可擴(kuò)展的方式處理PB級別的數(shù)據(jù)集。它特別適合處理非結(jié)構(gòu)化和半結(jié)構(gòu)化數(shù)據(jù)的批處理任務(wù)。圍繞其生態(tài)的Hive(數(shù)據(jù)倉庫)、HBase(NoSQL數(shù)據(jù)庫)等組件,共同構(gòu)成了一個強(qiáng)大的離線數(shù)據(jù)處理生態(tài)系統(tǒng),至今仍是許多企業(yè)大數(shù)據(jù)平臺的底層基礎(chǔ)。
2. Apache Spark:高速統(tǒng)一分析引擎
Spark被譽(yù)為Hadoop MapReduce的“繼任者”,其最大優(yōu)勢在于基于內(nèi)存的計算,速度比Hadoop MapReduce快上百倍。它提供了一個統(tǒng)一的框架,支持批處理、交互式查詢(Spark SQL)、實時流處理(Spark Streaming)、機(jī)器學(xué)習(xí)(MLlib)和圖計算(GraphX)。其易用的API(支持Scala, Java, Python, R)和卓越的性能,使其成為當(dāng)前進(jìn)行復(fù)雜數(shù)據(jù)分析、機(jī)器學(xué)習(xí)和實時處理的優(yōu)先選擇。
3. Snowflake:云端原生數(shù)據(jù)倉庫
Snowflake徹底革新了傳統(tǒng)數(shù)據(jù)倉庫的概念。它是一個完全托管、基于云的服務(wù),將存儲、計算與云服務(wù)層徹底分離。這種架構(gòu)帶來了無與倫比的彈性、可擴(kuò)展性和易用性。用戶可以獨立擴(kuò)展存儲和計算資源,按使用量付費,并輕松地跨AWS、Azure、GCP等云平臺共享數(shù)據(jù)。其高性能的SQL引擎和對半結(jié)構(gòu)化數(shù)據(jù)(如JSON)的原生支持,使其成為現(xiàn)代數(shù)據(jù)湖倉一體化的理想選擇。
4. Databricks:由Spark創(chuàng)始團(tuán)隊打造的Lakehouse平臺
Databricks提供了一個統(tǒng)一的、基于云的數(shù)據(jù)、分析和AI協(xié)作平臺。它首創(chuàng)了“Lakehouse”(湖倉一體)架構(gòu)理念,結(jié)合了數(shù)據(jù)湖的靈活性與數(shù)據(jù)倉庫的管理和性能。其核心引擎是高度優(yōu)化的Apache Spark,并集成了Delta Lake(提供ACID事務(wù))、MLflow(管理機(jī)器學(xué)習(xí)生命周期)和自動化ETL工具。Databricks極大地簡化了從數(shù)據(jù)準(zhǔn)備到高級分析和機(jī)器學(xué)習(xí)的工作流。
5. Google BigQuery:無服務(wù)器、高度可擴(kuò)展的數(shù)據(jù)倉庫
作為Google Cloud Platform的旗艦數(shù)據(jù)分析服務(wù),BigQuery是一個完全托管、無服務(wù)器的企業(yè)級數(shù)據(jù)倉庫。用戶無需管理任何基礎(chǔ)設(shè)施,只需將數(shù)據(jù)加載進(jìn)來,即可使用標(biāo)準(zhǔn)SQL對海量數(shù)據(jù)集進(jìn)行超高速的SQL查詢。它具備強(qiáng)大的機(jī)器學(xué)習(xí)集成能力(通過BigQuery ML)和出色的地理空間分析功能。其按查詢掃描的字節(jié)量付費的模式,對于間歇性或分析型負(fù)載極具成本效益。
6. Amazon EMR + AWS Glue:AWS生態(tài)的彈性處理與集成服務(wù)
在亞馬遜云科技(AWS)生態(tài)中,Amazon EMR(彈性MapReduce)是一個托管集群平臺,可輕松運行Hadoop、Spark、HBase、Presto等開源大數(shù)據(jù)框架,自動進(jìn)行資源配置和擴(kuò)展。而AWS Glue則是一個完全托管的ETL(提取、轉(zhuǎn)換、加載)服務(wù),它可以自動發(fā)現(xiàn)、編目數(shù)據(jù),并生成代碼來清洗、豐富和移動數(shù)據(jù)。兩者結(jié)合,為用戶在AWS上構(gòu)建自動化、可擴(kuò)展的數(shù)據(jù)處理管道提供了強(qiáng)大的一站式解決方案。
數(shù)據(jù)處理服務(wù)的關(guān)鍵考量
在選擇工具或服務(wù)時,企業(yè)需綜合評估:
- 數(shù)據(jù)類型與規(guī)模:是處理流數(shù)據(jù)還是批數(shù)據(jù)?數(shù)據(jù)量級如何?
- 性能要求:對查詢速度、吞吐量和延遲的敏感度。
- 技術(shù)棧與團(tuán)隊技能:現(xiàn)有基礎(chǔ)設(shè)施在云端還是本地?團(tuán)隊熟悉SQL還是編程?
- 總擁有成本(TCO):包括許可費、基礎(chǔ)設(shè)施成本、運維人力成本。
- 生態(tài)集成:與現(xiàn)有數(shù)據(jù)源、BI工具(如Tableau, Power BI)及業(yè)務(wù)系統(tǒng)的對接能力。
****
無論是開源的Hadoop、Spark,還是云原生的Snowflake、BigQuery、Databricks和AWS組合,這些頂尖工具和服務(wù)都在持續(xù)推動大數(shù)據(jù)處理與分析能力的邊界。沒有“唯一最好”的選擇,關(guān)鍵在于根據(jù)自身業(yè)務(wù)場景、技術(shù)架構(gòu)和成本預(yù)算,選擇最適合的“組合拳”,構(gòu)建敏捷、高效、智能的數(shù)據(jù)驅(qū)動體系,從而將海量數(shù)據(jù)轉(zhuǎn)化為切實的業(yè)務(wù)洞察與競爭優(yōu)勢。
如若轉(zhuǎn)載,請注明出處:http://m.oxysun.cn/product/85.html
更新時間:2026-04-15 11:55:37