借助混沌工程工具ChaosBlade構建高可用分布式數據處理服務
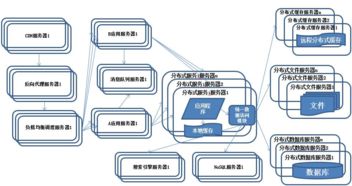
在當今以數據驅動的時代,分布式數據處理服務已成為企業核心基礎設施的關鍵組成部分。這些服務需要處理海量數據,并保證7x24小時的持續可用性。復雜的分布式環境充滿了不確定性,網絡延遲、硬件故障、依賴服務中斷等“混沌”事件時有發生。如何確保系統在面對這些不可避免的故障時依然堅如磐石?混沌工程為我們提供了答案,而ChaosBlade正是實踐這一理念的利器。
一、 混沌工程:從被動應對到主動防御
混沌工程是一種通過在生產環境中故意引入故障,以驗證系統在混亂條件下的韌性和可恢復性的學科。其核心思想是“未雨綢繆”,主動發現系統在設計和運維中隱藏的弱點,而不是等待真實故障發生后的被動救火。通過可控的實驗,團隊可以建立對系統行為的信心,并持續提升其高可用性。
二、 ChaosBlade:阿里開源的混沌實驗利器
ChaosBlade是一款功能強大、場景覆蓋全面的混沌實驗工具。它由阿里巴巴開源并長期維護,具有以下核心優勢:
- 場景豐富:支持從基礎設施(CPU、內存、磁盤、網絡)到應用層(JVM、HTTP、Dubbo、MySQL等)的廣泛故障注入場景,完美契合分布式數據處理服務(如Flink、Spark、Kafka等)的測試需求。
- 簡單易用:通過清晰的命令行工具或豐富的API,可以快速創建、管理和停止混沌實驗,學習成本低。
- 精準可控:能夠對實驗的爆炸半徑(影響范圍)、持續時間和故障類型進行精細控制,確保實驗安全。
- 開源開放:活躍的社區和良好的擴展性,允許用戶根據自身業務特點定制故障場景。
三、 構建高可用數據處理服務的實踐路徑
借助ChaosBlade,我們可以系統化地構建和驗證數據處理服務的高可用性,具體可分為四個階段:
階段一:定義穩態與假設
明確系統在正常情況下的“穩態”指標,例如數據處理延遲(P99)、吞吐量、成功率、積壓隊列長度等。然后,針對可能發生的故障(如Kafka Broker宕機、計算節點CPU滿載、網絡分區),提出“假設”,例如:“當某個TaskManager節點故障時,Flink作業應能在2分鐘內自動恢復,且數據不丟失。”
階段二:設計并執行混沌實驗
使用ChaosBlade將上述假設轉化為具體的實驗。例如:
- 資源層實驗:對運行Flink TaskManager的容器注入CPU滿載(blade create cpu load)或內存占用故障,觀察作業狀態與資源調度。
- 中間件層實驗:模擬Kafka Broker節點網絡延遲(blade create network delay)或丟包,測試Spark Streaming作業的容錯與反壓機制。
- 應用層實驗:模擬下游數據庫(如MySQL)慢查詢或連接失敗,驗證數據處理管道的降級與重試策略。
實驗應從開發環境開始,逐步向預發和生產環境推進,并嚴格控制爆炸半徑。
階段三:觀察與分析
在實驗過程中,密切監控系統穩態指標和業務指標的變化。通過日志、鏈路追蹤和監控儀表盤,深入分析系統行為:
- 故障是否被有效隔離?
- 自動恢復機制是否按預期觸發?
- 是否有級聯故障或雪崩效應?
- 告警系統是否及時響應?
階段四:修復與固化
根據實驗結果,識別系統中的脆弱點。這可能是缺少重試機制、熔斷器配置不合理、資源配額不足,或是監控盲區。修復問題后,將成功的混沌實驗固化為自動化測試用例,集成到CI/CD流水線中,形成常態化的韌性驗證機制。
四、 關鍵注意事項
- 安全第一:始終在可控范圍內進行實驗,使用白名單、最小爆炸半徑等策略,避免對生產業務造成實質性損害。
- 團隊協作:混沌工程需要開發、測試、運維及SRE團隊的共同參與,建立統一的故障認知和應急流程。
- 持續迭代:高可用建設不是一勞永逸的。隨著系統架構演進和新功能引入,需要持續設計新的實驗進行驗證。
在分布式系統的復雜性面前,脆弱性始終存在。借助ChaosBlade實踐混沌工程,使我們能夠變被動為主動,將不確定性轉化為提升系統韌性的驅動力。通過持續地“搞破壞”來驗證和加固,我們最終能夠構建出真正意義上高可用、可信賴的分布式數據處理服務,為業務的穩定運行保駕護航。從今天開始,不妨用一次小規模的ChaosBlade實驗,邁出主動擁抱混沌、構建系統韌性的第一步。
如若轉載,請注明出處:http://m.oxysun.cn/product/87.html
更新時間:2026-04-19 23:15:51